30 Zastosowania
Zaprezentujemy teraz zastosowania CTG Lindeberga-Fellera
30.1 Liczba cykli w losowej permutacji
Zaczniemy od przykładu twierdzenia granicznego opisującego liczbę cykli w losowej permutacji. Przypomnijmy, że każdą permutację można jednoznacznie przedstawić jako złożenie rozłącznych cykli, np. \[\begin{equation}%\label{eq:per} (3\ 9\ 6\ 8\ 2\ 1\ 5\ 4\ 7) = (1\ 3\ 6) (2\ 9\ 7\ 5) (4\ 8). \tag{30.1} \end{equation}\] Problem jest następujący: losujemy jednostajnie permutację \(\pi\in \mathcal{S}_n\) (\(\mathcal{S}_n\) jest grupą permutacji zbioru \(n\)-elementowego) i chcemy określić liczbę jej cykli \(C_n(\pi)\), gdy \(n\to \infty\). Jest to oczywiście pewna wartość losowa. Aby zobaczyć czego możemy się spodziewać po zachowaniu \(C_n\) możemy wylosować \(20000\) permutacji ze zbioru \(\mathcal{S}_{1000}\) i przeanalizować liczbę ich cykli na histogramie.
# Funkcja zliczająca liczbę cykli w permutacji
count_cycles <- function(perm) {
n <- length(perm)
visited <- rep(FALSE, n)
cycles <- 0
for (i in 1:n) {
if (!visited[i]) {
j <- i
while (!visited[j]) {
visited[j] <- TRUE
j <- perm[j]
}
cycles <- cycles + 1
}
}
return(cycles)
}
# Parametry
n <- 1000 # rozmiar permutacji (duży)
num_samples <- 20000 # większa liczba prób dla lepszej estymacji
# Kolory (Solarized)
bg_color <- "#002b36"
fg_color <- "#eee8d5"
primary_color <- "#2aa198"
ref_line_color <- "#586e75"
# Generowanie danych
set.seed(123)
cycle_counts <- replicate(num_samples, count_cycles(sample(n)))
# Ustawienia graficzne
par(bg = bg_color, fg = fg_color, col.axis = fg_color, col.lab = fg_color, col.main = fg_color)
# Histogram
hist(cycle_counts,
breaks = min(cycle_counts):max(cycle_counts),
main = paste("Histogram liczby cykli (n =", n, ")"),
xlab = "Liczba cykli",
ylab = "Częstość",
col = primary_color,
border = ref_line_color)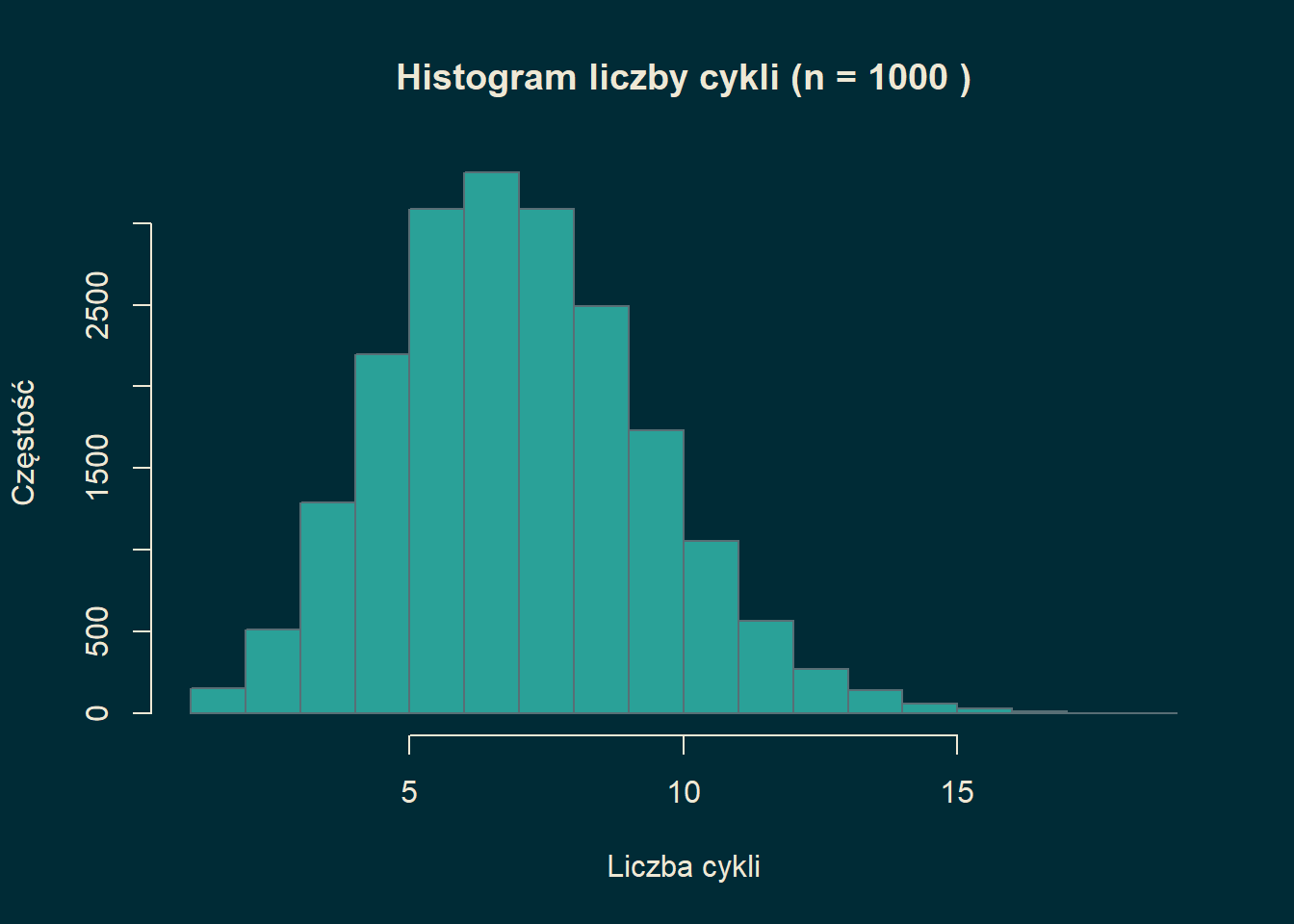
Widzimy, że wartości układają się bardzo regularnie. Kształt histogramu sugeruje, że graniczne \(C_n\) powinno mieć rozkład normalny. Naszym celem będzie udowodnienie twierdzenia
Twierdzenie 30.1 Niech \(C_n\) oznacza liczbę cykli w losowej permutacji z \(\mathcal{S}_n\). Wówczas \[ \frac{C_n -\log n}{\sqrt{\log n}} \Rightarrow \mathcal{N}(0,1). \]
Powyższy wynik mówi, że liczba cykli w losowej permutacji jest rzędu \[ C_n\approx \log n + \sqrt{\log n}\; Y \] dla \(Y\sim \mathcal{N}(0,1)\). Typowa permutacja ma zatem \(\log(n) \pm \sqrt{\log(n)}\) cykli. W szczególności, aby udowodnić to twierdzenie pokażemy, że \(\mathbb{E}[ C_n ] \sim \log n\) oraz \(\mathbb{V}ar [C_n] \sim \log n\).
Zanim przedstawimy dowód twierdzenia, pokażemy jak odnieść ten problem do schematów serii. Mianowicie, każdej permutacji \(\pi\) możemy więc przyporządkować napis (jak powyżej w (30.1)). Zdefiniujmy zmienne losowe \[ Z_{n,k} = \left\{ \begin{array}{cc} 1, & \mbox{ jeżeli $k$-ta liczba zamyka cykl} \\ 0, & \mbox{ w przeciwnym razie}\\ \end{array} \right. \] Innymi słowy \(Z_{n,k}=1\), gdy prawy nawias pojawia się w rozkładzie \(\pi\) na cykle po \(k\)-tej liczbie w ciągu. W powyższym przykładzie mamy więc \(Z_{9,3} = Z_{9,7} = Z_{9,9}= 1\). Zauważmy, że wówczas \[ C_n = Z_{n,1} + \ldots + Z_{n,n} \] jest liczbą cykli w permutacji \(\pi\). Kluczowy w dowodzie twierdzenia jest lemat.
Lemma 30.1 Dla ustalonego \(n\), zmienne losowe \(Z_{n,1}, \ldots, Z_{n,n}\) są niezależne oraz \[\mathbb{P}[Z_{n,j}=1] = \frac 1{n-j+1}\] dla \(j \leq n\).
Proof. W dowodzie będziemy konstruować krok po kroku losową permutację. Będziemy to robić poprzez losowanie kolejno cykli. Będziemy losować bez zwracania liczby \(j_1, j_2, \ldots\) i z nich będziemy konstruować pierwszy cykl \[ 1\to j_1 \to j_2 \to \ldots \to j_k=1. \] aż do momentu pojawienia się jedynki. Po wylosowaniu pierwszego cyklu wybierzemy najmniejszą niewykorzystaną jeszcze liczbę \(l\) i zaczniemy losować kolejne liczby \(l_1, l_2, \ldots\) bez zwracania ze zbioru \(\{1, \ldots , n\} \setminus \{j_1, \ldots , j_k\}\) i formować z nich drugi cykl \[ l \to l_1 \to l_2 \to \ldots \to l_m = l \] aż do momentu pojawienia się liczby \(l\). Procedurę tę kontynuujemy aż do wyczerpania wszystkich liczb z \(\{2, \ldots, n\}\). Procedurę obrazują symulacje dla \(n=40\).
Algorytm ten możemy zapisać formalnie. W tym celu będziemy losować kolejno liczby \(j_1,\ldots,j_n\) ze zbioru \(\{1,\ldots,n\}\). W taki sposób, że \(j_1\) jest jednostajnie wylosowaną liczbą z tego zbioru, a \(j_k\) jest jednostajnie wylosowane ze zbioru \(\{1,\ldots, n\}\setminus \{ j_1,\ldots, j_{k-1}\}\). Na podstawie ciągu \(\{j_k\}\) zostanie stworzona losowa permutacja. Elementy tego ciągu to będą odpowiednie elementy permutacji, w zmienionej jednak kolejności, dokładnie takiej jaka występuje przy rozkładzie permutacji na rozłączne cykle (taki rozkład jest jednoznaczny jeżeli założymy dodatkowo, że najmniejsze liczby z kolejnych cykli są posortowane rosnąco). Konstrukcja będzie prowadziła do jednostajnie losowej permutacji (wylosowanej w sposób jednostajny ze zbioru \(S_n\)). Sama permutacja będzie zależeć jednak od drugiego ciągu, który będzie potrzebny, aby określić strukturę cykli w permutacji i obserwować, czy wylosowanie kolejnej liczby zamyka cykl. Ta dodatkowa informacja będzie zawarta w drugim ciągu \(\{i_k\}\) i to ona będzie kluczowa w dowodzie lematu.
Krok 1: Przyjmujemy \(i_1 = 1\), a \(j_1\) jest losową liczbą ze zbioru \(\{1,\ldots,n\}\), i definiujemy \(\pi(i_1) = j_1\) (np. \(j_1 = 3\)). Dalej rozpatrujemy dwa przypadki:
- jeżeli \(j_1=1\) (zamknęliśmy cykl), to kładziemy \(i_2 = 2\) (otwieramy nowy cykl);
- jeżeli \(j_1\not=1\), to przyjmujemy \(i_2 = j_1\)
Krok 2: Mamy zdefiniowane \((i_1, i_2)\) oraz \(j_1\). Losujemy \(j_2\) jednostajnie ze zbioru \(\{1,\ldots,n\}\setminus \{j_1\}\) (np. \(j_2 = 6\)) i przyjmujemy \(\pi(i_2)=j_2\). Ponownie rozpatrujemy dwa przypadki:
- jeżeli \(j_2\in \{i_1,i_2\}\) (zamknęliśmy cykl), to jako \(i_3\) przyjmujemy najmniejszą niewylosowaną do tej pory liczbę (otwieramy nowy cykl);
- jeżeli \(j_2\notin\{i_1,i_2\}\), to przyjmujemy \(i_3 = j_2\).
Krok k: Wybraliśmy już liczby \(i_1,\ldots, i_{k}\) oraz \(j_1,\ldots, j_{k-1}\). Losujemy \(j_k\) ze zbioru \(\{1, \ldots, n\}\setminus \{i_1, \ldots, i_k\}\) Kładziemy \(\pi(i_k) = j_k\).
- Jeżeli \(j_{k-1}\in \{i_1,\ldots,i_{k}\}\) - oznacza to, że \(j_{k}\) domknął cykl i przyjmujemy \(i_{k+1} = \min\{ 1,2,\ldots, n \}\setminus\{i_1,\ldots,i_{k}\}\);
- \(j_{k}\notin \{i_1,\ldots,i_{k}\}\) - oznacza to, że \(j_{k}\) nie domknął cyklu i przyjmujemy \(i_{k+1} = j_{k}\).
Przykładowo, jeżeli w kolejnych krokach wylosujemy liczby 3,6,1,9,7,5,2,8,4, to otrzymamy permutację (30.1).
Zauważmy, że rozkład opisanej powyżej permutacji jest jednostajny. Wynika to z obserwacji, że jeżeli ustalimy permutację, rozbijemy ją na rozłączne cykle, to wylosujemy ją przy pomocy powyższego algorytmu z prawdopodobieństwem \(1/n!\) (bo w każdym kroku musimy losować kolejne pojawiające się liczby).
Można też natychmiast zauważyć, że \[ \mathbb{P}[Z_{n,k}=1] = \frac 1{n-k+1}, \] bo w \(k\)-tym kroku pozostało \(n-k+1\) liczb i tylko jedna z nich może zamknąć cykl.
Pozostaje więc do pokazania, że zmienne losowe \(Z_{n,k}\) są niezależne. Wynika to z obserwacji, że wartość \(Z_{n,k}\) nie zależy od poprzednich losowań i struktury cykli.
Proof (Dowód twierdzenia 30.1). Przypomnijmy, że naszym celem jest zbadanie liczby cykli w losowej permutacji \(C_n = Z_{n,1} + \ldots + Z_{n,n}\). Wygodniej będzie ponumerować te zmienne losowe od końca, tzn. zdefiniujmy \[ Y_{n,k} = Z_{n,n-k+1}. \] Wówczas \(Y_{n,1},\ldots, Y_{n,n}\) są niezależnymi zmiennymi losowymi takimi, że \[ \mathbb{P}[Y_{n,m}=1] = \frac 1m, \quad \mathbb{P}[Y_{n,m} = 0] = 1-\frac 1m. \] Implikuje to \[\mathbb{E} Y_{n,m} = \frac 1m,\qquad \mathbb{V}ar Y_{n,m} = \frac 1m-\frac 1{m^2}. \] Korzystając z \(C_n = Y_{n,1}+\ldots+ Y_{n,n}\), otrzymujemy \[\mathbb{E} [C_n] = \sum_{m=1}^n \frac 1m \sim \log n, \qquad \mathbb{V}ar [C_n] \sim \log n.\] Niech \[ X_{n,m} = \frac{Y_{n,m} - \frac 1m}{\sqrt{\log n}} \] będzie schematem serii (niezależność \(\{X_{n,m}\}_m\) przy ustalonym \(n\) wynika z niezależności \(\{Y_{n,m}\}_m\)). Pokażemy, że spełnia on założenie twierdzenia Lindeberga-Fellera. Istotnie \(\mathbb{E} [X_{n,m}]=0\) oraz \[s_n^2 = \sum_{m=1}^n \mathbb{V}ar [X_{n,m}] = \frac 1{\log n} \sum_{m=1}^n \mathbb{V}ar(Y_{n,m}) = \frac 1{\log n} \bigg( \sum_{m=1}^n \frac 1m - \sum_{m=1}^n \frac 1{m^2} \bigg) \to 1.\] Sprawdźmy teraz ostatni warunek. Ustalmy \(\varepsilon >0\) i zauważmy, że dla dużych wartości \(n\) \[ \sum_{m=1}^n \mathbb{E}\big[X_{n,m}^2 {\bf 1}_{\{|X_{n,m}|>\varepsilon\}} \big] = 0, \] ponieważ \(|X_{n,m}|< 1/\sqrt{\log n}<\varepsilon\).
Zatem z centralnego twierdzenia granicznego Lindeberga-Fellera \[ X_{n,1}+\ldots + X_{n,n} \Rightarrow \mathcal{N}(0,1), \] a to z kolei implikuje. \[ \frac{C_n - \sum_{m=1}^n \frac 1n}{\sqrt{\log n}} \Rightarrow \mathcal{N}(0,1). \] Ostatecznie ponieważ \(|\sum_{m=1}^n \frac 1n - \log n|\le 1\), to \[ \frac{C_n -\log n}{\sqrt{\log n}} \Rightarrow \mathcal{N}(0,1), \] co kończy dowód twierdzenia.
30.1.1 Twierdzenie graniczne dla liczb pierwszych
Podobne metody (dowód jest jednak nieco trudniejszy) prowadzą do następującego wyniku:
Twierdzenie 30.2 (Centralne Twierdzenie Graniczne Erdősa-Kaca) Niech \(X\) będzie losową liczbą ze zbioru \(\{1,\ldots,n\}\) i niech \(g(X)\) będzie liczbą dzielników \(X\). Wtedy \[ \frac{g(X) - \log\log n}{\sqrt{\log\log n}} \Rightarrow \mathcal{N}(0,1). \]
Powyższe twierdzenie mówi więc, że \(g(X)\approx\log\log n + \sqrt{\log\log n}\;Y\). Zwróćmy jednak uwagę, że podwójny logarytm powoduje, że ten wynik ma sens dla naprawdę dużych liczb, gdyż \(e^{e^4}\approx 5\cdot 10^{23}\).