3 Model neuronu
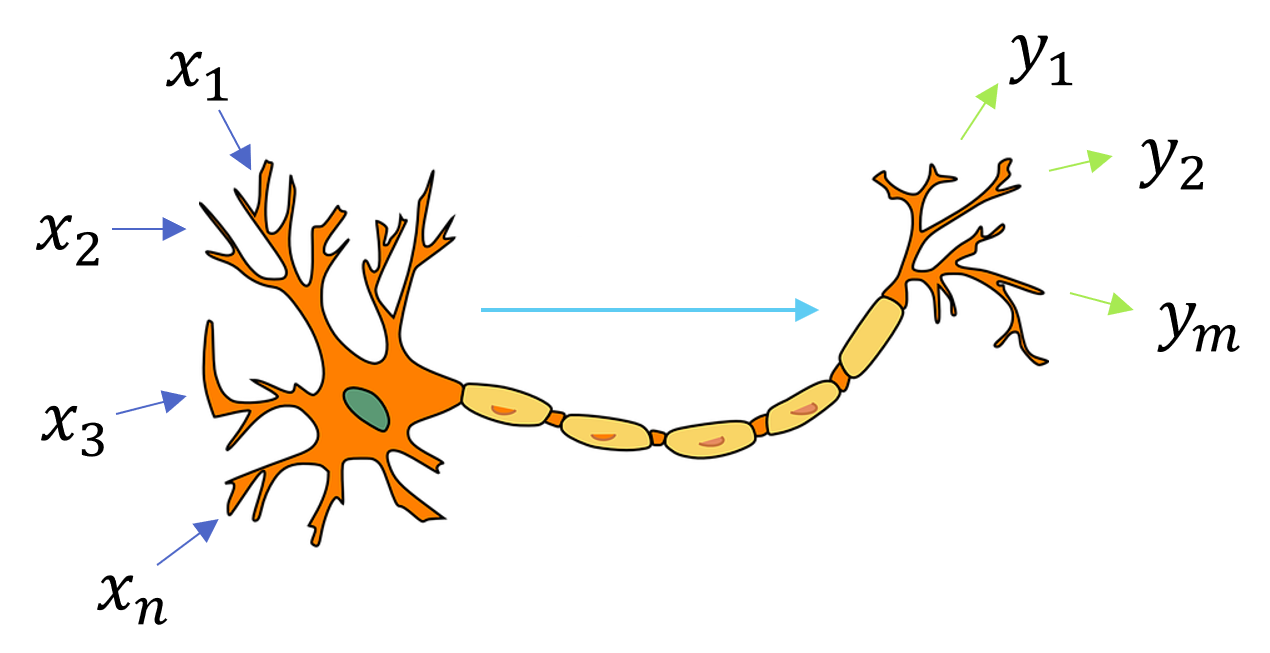
Jak sama nazwa wskazuje, sztuczne sieci neuronowe są inspirowane biologią. Podobnie jak ich biologiczne odpowiedniki, składają się one ze sztucznych neuronów. Podstawową strukturę biologicznego neuronu przedstawiono na Rysunek 3.1. Każdy neuron może wysyłać i odbierać sygnały do oraz od innych neuronów, dzięki czemu wspólnie tworzą one sieć.
Jeden z pierwszych matematycznych modeli neuronu został zaproponowany przez Warrena MuCullocha (Rysunek 3.2) oraz Waltera Pittsa (Rysunek 3.3) w 1943 roku McCulloch i Pitts (1943).


Sztuczne sieci neuronowe składają się ze sztucznych neuronów. Każdy sztuczny neuron przyjmuje pewne wejścia, zwykle w postaci liczb rzeczywistych, i generuje jedno lub więcej wyjść, również zwykle będących liczbami rzeczywistymi, które przekazuje do innych neuronów.
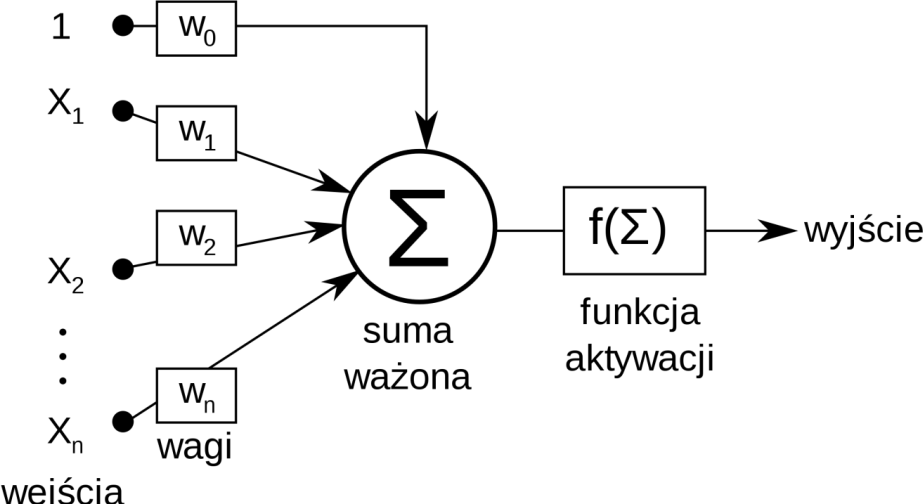
Najczęściej stosowany model neuronu jest dany przez transformację afiniczną, po której następuje nieliniowa funkcja aktywacji. Niech \(x \in \mathbb{R}^n\) oznacza sygnał wejściowy, a \(y \in \mathbb{R}^m\) sygnał wyjściowy. Wtedy obliczamy
\[ y = \sigma(Ax + b), \tag{3.1}\]
gdzie \(A \in \mathbb{R}^{m \times n}\), \(b \in \mathbb{R}^m\), a \(\sigma\) jest wybraną funkcją aktywacji. Elementy macierzy \(A\) nazywa się wagami liniowymi, natomiast wektor \(b\) nazywa się biasem lub wyrazem wolnym. Wartość pośrednia \(Ax + b\) bywa nazywana aktywacją. Funkcja aktywacji \(\sigma\) bywa również nazywana funkcją transferu lub nieliniowością.
Wejścia i wyjścia nie muszą obejmować wszystkich liczb rzeczywistych. W zależności od zastosowania możemy spotkać między innymi:
- \(\{0, 1\}\): wartości binarne,
- \(\mathbb{R}^+\): nieujemne liczby rzeczywiste,
- \([0,1]\): przedziały, na przykład prawdopodobieństwa,
- \(\mathbb{C}\): liczby zespolone,
Historycznie istotnym wyborem funkcji aktywacji jest funkcja Heaviside’a, dana wzorem
\[ H(x) = \mathbb{1}_{x \geq 0}(x) = \begin{cases} 1, & x \geq 0, \\ 0, &x<0. \end{cases} \]
Neuron postaci Równanie 3.1, który używa funkcji Heaviside’a jako funkcji aktywacji, nazywa się perceptronem. Zobaczmy, co można z nim zrobić.
Przykład 3.1 Niech \(w \in \mathbb{R}^n\) oraz \(b \in \mathbb{R}\). Wtedy neuron o wejściu \(x \in \mathbb{R}^n\) i wyjściu \(y \in \mathbb{R}\) ma postać
\[ H(w^Tx + b) = \begin{cases} 1 & w^Tx \geq -b, \\ 0 & w^Tx < -b. \end{cases} \]
Jest to nic innego jak liniowy klasyfikator binarny na \(\mathbb{R}^n\), ponieważ \(w^Tx = -b\) jest hiperpłaszczyzną w \(\mathbb{R}^n\). Ta hiperpłaszczyzna dzieli przestrzeń na dwie części i przypisuje wartość \(0\) jednej połowie oraz wartość \(1\) drugiej. Dla \(n=2\) wygląda to następująco:
Kolorem niebieskim zaznaczyliśmy obszar tych \(x\) dla których \(H(w^Tx+b)>0\). Kolorem czerwonym zaś \(H(w^Tx+b)<0\).
Przykład 3.2 Możemy między innymi użyć perceptronu do modelowania elementarnej logiki boolowskiej. Niech \(x_1, x_2 \in \{0,1\}\) oraz niech
\[ \operatorname{AND}(x_1,x_2) = H(x_1+x_2-1.5). \]
Wtedy neuron zachowuje się następująco:
| \(x_1\) | \(x_2\) | \(\operatorname{AND}(x_1,x_2)\) |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 1 |
Ćwiczenie 3.1 Zaimplementuj wszystkie znane sobie operacje logiczne.
Funkcja Heaviside’a jest przykładem skalarnej lub punktowej funkcji aktywacji. Często, gdy używamy funkcji skalarnej jako funkcji aktywacji, nadużywamy notacji i pozwalamy, aby przyjmowała ona wektory oraz macierze w następujący sposób. Niech \(\sigma: \mathbb{R} \to \mathbb{R}\). Wtedy dopuszczamy zapis
\[ \sigma \left( \begin{bmatrix} x_1 \\ \vdots \\ x_n \end{bmatrix} \right) \equiv \begin{bmatrix} \sigma(x_1) \\ \vdots \\ \sigma(x_n) \end{bmatrix}. \]
Poniżej wymieniamy kilka powszechnie używanych skalarnych funkcji aktywacji.
Rectified Linear Unit (ReLU), czyli rektyfikowana jednostka liniowa: prawdopodobnie najczęściej używana funkcja aktywacji we współczesnych sieciach neuronowych. Definiuje się ją jako
\[ \sigma(\lambda) = \mathrm{ReLu}(\lambda) = \max\{0, \lambda\}. \]
Pokaż kod
import numpy as np
import matplotlib.pyplot as plt
x_left = np.linspace(-5, 0, 250)
x_right = np.linspace(0, 5, 250)
y_left = np.zeros_like(x_left)
y_right = x_right
fig, ax = plt.subplots(figsize=(7, 4))
ax.plot(x_left, y_left, linewidth=3, label=r"$0$ dla $x < 0$")
ax.plot(x_right, y_right, linewidth=3, label=r"$x$ dla $x \geq 0$")
ax.scatter([0], [0], s=50, zorder=3)
ax.axhline(0, color="black", linewidth=1)
ax.axvline(0, color="black", linewidth=1)
ax.set_xlabel(r"$x$")
ax.set_ylabel(r"$\operatorname{ReLU}(x)$")
ax.set_title(r"$\operatorname{ReLU}(x)=\max(0,x)$")
ax.set_xlim(-5, 5)
ax.set_ylim(-0.5, 5.5)
ax.grid(True, alpha=0.3)
ax.legend()
plt.show()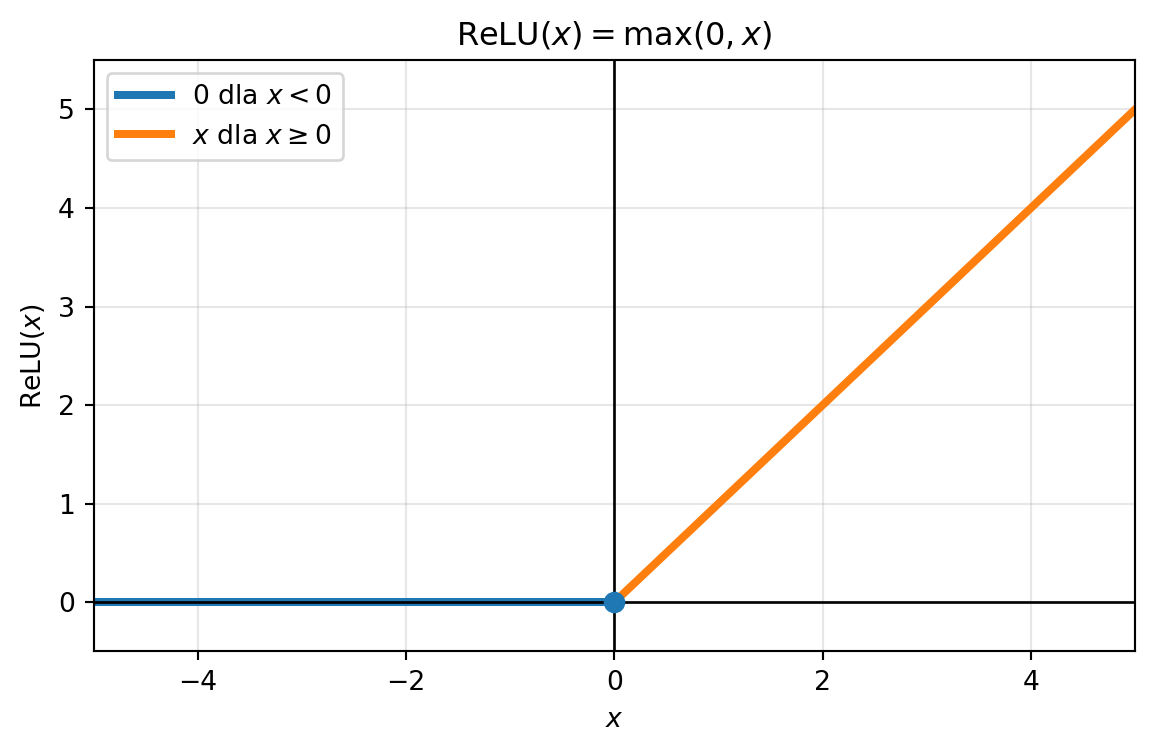
Sigmoid, znana również jako sigmoida logistyczna lub funkcja miękkiego progu: \[ \sigma(\lambda) := \frac{1}{1 + e^{-\lambda}}. \] Sigmoida była często używana jako funkcja aktywacji we wczesnych sieciach neuronowych. Z tego powodu funkcje aktywacji w ogólności nadal często oznacza się symbolem \(\sigma\).
Pokaż kod
import numpy as np
import matplotlib.pyplot as plt
# Zakres argumentów
x = np.linspace(-10, 10, 1000)
# Funkcja sigmoid
y = 1 / (1 + np.exp(-x))
# Rysunek
fig, ax = plt.subplots(figsize=(7, 4))
ax.plot(x, y, linewidth=3, label=r"$\sigma(x)=\frac{1}{1+e^{-x}}$")
# Osie
ax.axhline(0, color="black", linewidth=1)
ax.axvline(0, color="black", linewidth=1)
# Asymptoty poziome
ax.axhline(1, linestyle="--", linewidth=1, label=r"$y=1$")
ax.axhline(0, linestyle="--", linewidth=1, label=r"$y=0$")
# Punkt środkowy
ax.scatter([0], [0.5], s=50, zorder=3)
ax.annotate(
r"$(0,\frac{1}{2})$",
xy=(0, 0.5),
xytext=(0.8, 0.42),
arrowprops=dict(arrowstyle="->")
)
# Opisy
ax.set_xlabel(r"$x$")
ax.set_ylabel(r"$\sigma(x)$")
ax.set_title("sigmoid")
ax.set_xlim(-10, 10)
ax.set_ylim(-0.1, 1.1)
ax.grid(True, alpha=0.3)
ax.legend()
plt.show()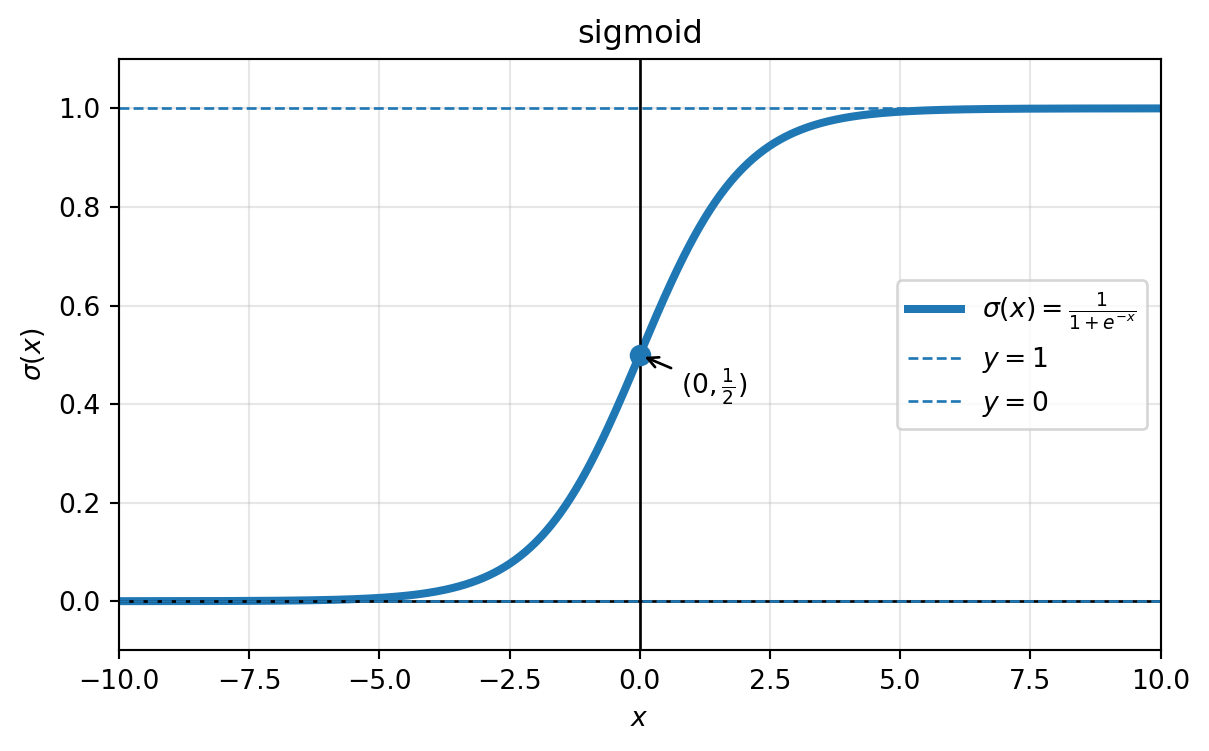
Tangens hiperboliczny: funkcja bardzo podobna do sigmoidy, dana wzorem
\[ \tanh(\lambda) := \frac{e^\lambda - e^{-\lambda}}{e^\lambda + e^{-\lambda}}. \]
Pokaż kod
import numpy as np
import matplotlib.pyplot as plt
# Zakres argumentów
x = np.linspace(-5, 5, 1000)
# Funkcja tangens hiperboliczny
y = np.tanh(x)
# Rysunek
fig, ax = plt.subplots(figsize=(7, 4))
ax.plot(x, y, linewidth=3, label=r"$\tanh(x)$")
# Osie
ax.axhline(0, color="black", linewidth=1)
ax.axvline(0, color="black", linewidth=1)
# Asymptoty poziome
ax.axhline(1, linestyle="--", linewidth=1, label=r"$y=1$")
ax.axhline(-1, linestyle="--", linewidth=1, label=r"$y=-1$")
# Punkt środkowy
ax.scatter([0], [0], s=50, zorder=3)
ax.annotate(
r"$(0,0)$",
xy=(0, 0),
xytext=(0.5, -0.3),
arrowprops=dict(arrowstyle="->")
)
# Opisy
ax.set_xlabel(r"$x$")
ax.set_ylabel(r"$\tanh(x)$")
ax.set_title("tangens hiperboliczny")
ax.set_xlim(-5, 5)
ax.set_ylim(-1.2, 1.2)
ax.grid(True, alpha=0.3)
ax.legend()
plt.show()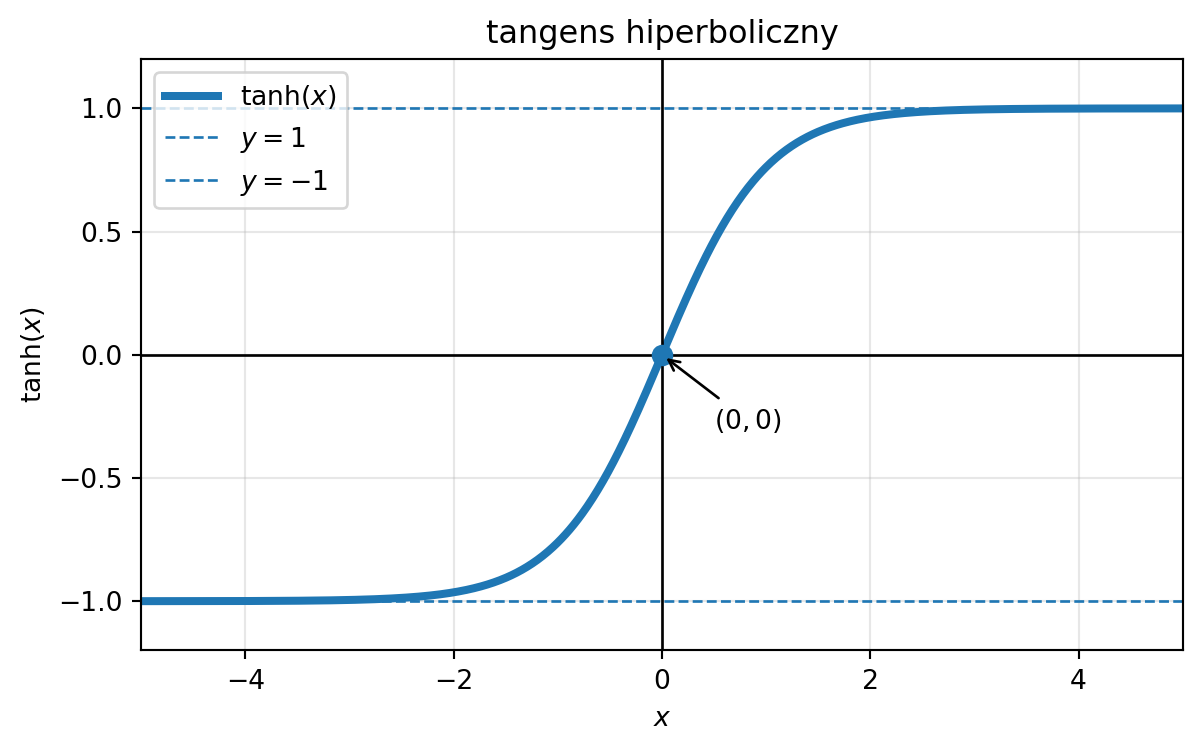
Swish: nowsza funkcja aktywacji, którą można rozumieć jako gładki wariant funkcji ReLU. Jest dana przez przemnożenie wejścia przez funkcję sigmoidalną: \[ \operatorname{swish_\beta}(\lambda) := \lambda \, \sigma(\beta\lambda) := \frac{\lambda}{1 + e^{-\beta \lambda}}, \] gdzie \(\beta > 0\). Parametr \(\beta\) zwykle wybiera się jako równy \(1\), ale w razie potrzeby można go traktować jako parametr uczony. W przypadku \(\beta=1\) funkcję tę nazywa się również sigmoid-weighted linear unit, czyli SiLU.
Pokaż kod
import numpy as np
import matplotlib.pyplot as plt
# Zakres argumentów
x = np.linspace(-10, 10, 1000)
# Funkcja sigmoid
sigmoid = 1 / (1 + np.exp(-x))
# Funkcja Swish
y = x * sigmoid
# Rysunek
fig, ax = plt.subplots(figsize=(7, 4))
ax.plot(
x,
y,
linewidth=3,
label=r"$\operatorname{Swish}(x)=x\sigma(x)=\frac{x}{1+e^{-x}}$"
)
# Osie
ax.axhline(0, color="black", linewidth=1)
ax.axvline(0, color="black", linewidth=1)
# Punkt w zerze
ax.scatter([0], [0], s=50, zorder=3)
ax.annotate(
r"$(0,0)$",
xy=(0, 0),
xytext=(0.8, -0.8),
arrowprops=dict(arrowstyle="->")
)
# Opisy
ax.set_xlabel(r"$x$")
ax.set_ylabel(r"$\operatorname{Swish}(x)$")
ax.set_title("Swish")
ax.set_xlim(-10, 10)
ax.set_ylim(-1, 10)
ax.grid(True, alpha=0.3)
ax.legend()
plt.show()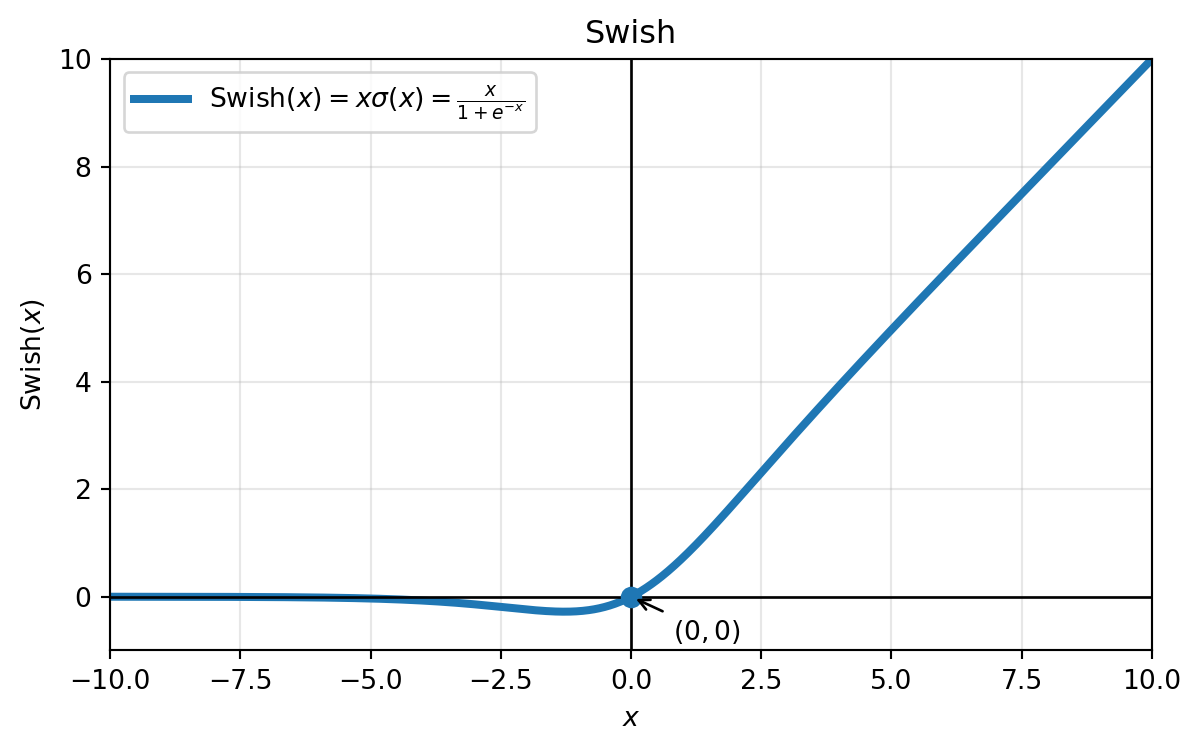
Funkcje aktywacji nie muszą być skalarne. Poniżej wymieniamy kilka powszechnych funkcji wielu zmiennych.
Softmax, znana również jako znormalizowana funkcja wykładnicza: \(\operatorname{softmax}:\mathbb{R}^n \to [0,1]^n\) jest dana wzorem \[ \operatorname{softmax} \left( \begin{bmatrix} x_1 \\ x_2 \\ \vdots \\ x_n \end{bmatrix} \right) := \frac{1}{\sum_{i=1}^n e^{x_i}} \begin{bmatrix} e^{x_1} \\ e^{x_2} \\ \vdots \\ e^{x_n} \end{bmatrix}. \] Softmax ma użyteczną własność: jego wyjście jest dyskretnym rozkładem prawdopodobieństwa, tzn. każda wartość jest nieujemną liczbą rzeczywistą z przedziału \([0,1]\), a wszystkie wartości wyjściowe sumują się dokładnie do \(1\).
Maxpool: w tym przypadku każde wyjście jest maksimum pewnego podzbioru wejść. Funkcja \(\operatorname{maxpool}:\mathbb{R}^n \to \mathbb{R}^m\) jest dana wzorem \[ \operatorname{maxpool} \left( \begin{bmatrix} x_1 \\ x_2 \\ \vdots \\ x_n \end{bmatrix} \right) := \begin{bmatrix} \max_{j \in I_1} x_j \\ \max_{j \in I_2} x_j \\ \vdots \\ \max_{j \in I_m} x_j \end{bmatrix}. \] Dla każdego \(i \in \{1,\ldots,m\}\) mamy zbiór \(I_i \subset \{1,\ldots,n\}\), który określa, po których wejściach należy wziąć maksimum dla danego wyjścia. Maxpooling można łatwo uogólnić, zastępując operację maksimum operacją minimum, średnią arytmetyczną, średnią innego typu itd.