Istnieje kilka sposobów poznawania otaczającego nas świata. Paradygmaty kilku z nich widać w metodach uczenia maszynowego.
Uczyć się możemy od nauczyciela, który pokazuje nam błędy w wypracowaniach czy rachunkach. Może być to też rodzic z małym dzieckiem, który opowiada mu otaczający go świat (na widok psa tłumaczy dziecku “to jest pies”). Mówimy wówczas o uczeniu nadzorowanym.
Możemy uczyć się sami. Po wysłuchaniu kilku utworów muzycznych lub obejrzeniu kilku filmów sami zaczynamy dostrzegać pewne powtarzające się motywy. Dziecko bawiące się samodzielnie samo zauważa, że okrągłe przedmioty się toczą. Są to przykłady uczenia nienadzorowanego. Jest to pewnego rodzaju porządkowanie doświadczenia. Umysł nie tylko biernie odbiera dane, ale sam szuka regularności i tworzy kategorie.
Możemy też uczyć się przez konsekwencje. Dziecko może raz dotknąć gorącego kubka, po czym więcej tak nie zrobi. Ogólniej człowiek uczy się ostrożności po bolesnym błędzie. Podczas tresury psy są wynagradzane przez swoich właścicieli przysmakami. Są to przykłady uczenia przez wzmacnianie.
W tym momencie można zapytać jeszcze co co znaczy nauczyć się czegoś. Oznacza to opanowanie pewnej umiejętności na tyle, by móc ją powtarzać w zmieniających się warunkach. Aby móc doprecyzować to stwierdzenie, będziemy skupiać się od tej pory na uczeniu nadzorowanym.
Przykład 2.1 Student na kursie algebry liniowej uczy się liczyć wyznaczniki macierzy \(3\times 3\). Jego celem jest wykazanie się tą umiejętnością na kolokwium. Oznacza to, że musi być w stanie policzyć wyznacznik dowolnej macierzy \(3\times 3\) nawet jeżeli nie widział jej wcześniej. Wyznacznik macierzy \(\det\) to funkcja ze zbioru macierzy \(M_{3\times 3}\) w zbiór liczb rzeczywistych \(\mathbb{R}\). Matematycznie możemy powiedzieć, że w trakcie nauki student oblicza wartości wyznacznika \(\det(m)\) dla macierzy \(m\) pochodzących z pewnego podzbioru \(A \subseteq M_{3 \times 3}\) macierzy na których się uczy. W trakcie kolokwium student ma za zadanie wykazać się umiejętnością obliczenia wyznacznika macierzy spoza zbioru \(A\).
W podobnym duchu będziemy rozumieli nauczenie się czegoś przez maszynę. Chcemy aby program komputerowy był w stanie obliczyć wartość funkcji \(f \colon \mathcal{X} \to \mathcal{Y}\). Oczywiście w przypadku niewielkich dziedzin \(X\) i łatwych odwzorowań \(f\) możemy podać komputerowi jawny wzór funkcji \(f\). Wyzwanie pojawie się w momencie, w którym przestrzeń \(X\) staje się duża, a interesująca nas funkcja \(f\) zbyt złożona aby móc podać ją bezpośrednim wzorem.
Przykład 2.2 W trakcie nauki czytania pisma odręcznego dziecko uczy się rozpoznawać litery. Dziecko rozpoznaje literę alfabetu na podstawie obrazka o wymiarach \(h\times w\). Matematycznie jest to funkcja z podzbioru czarno-białych obrazków \(X\subseteq \{0,1\}^{h \times w}\) (wykluczając pewne patologiczne przykłady) w alfabet \(Y = \{a, b, \ldots, z\}\). Jeżeli \(X\) składa się z czytelnych liter, to \(f\) jest dobrze określoną funkcją, ponieważ dla każdego czytelnego obrazka \(x \in X\) potrafimy jednoznacznie odczytać zapisaną na nim literę \(f(x)\). Napisanie jednak \(f\) wzorem ogólnym jest praktycznie niemożliwe.
Zauważmy, że Przykład 2.1 oraz Przykład 2.2 są fundamentalnie różne. W przypadku pierwszego stanieje jawna procedura postępowania. W drugim przypadku nie jesteśmy w stanie efektywnie wyznaczyć procedury. Okazuje się jednak, że jesteśmy w stanie
2.2 Problem uczenia nadzorowanego
Uczenie nadzorowane to paradygmat uczenia maszynowego, w którym dostępne dane składają się z par wejść oraz znanych, poprawnych wyjść. Nieznane jest natomiast to, jak dokładnie działa odwzorowanie między tymi wejściami i wyjściami. Celem jest wywnioskowanie, na podstawie dostępnych danych, ogólnej struktury tego odwzorowania, w nadziei, że będzie ono uogólniać się na niewidziane wcześniej sytuacje. Formalnie problem ten możemy sformułować następująco. Szukana funkcja \(f \colon \mathcal{X} \to \mathcal{Y}\) między przestrzeniami \(\mathcal{X}\) oraz \(\mathcal{Y}\). Znamy wartości funkcji \(f\) na pewnym podzbiorze \(\mathcal{A} \subseteq \mathcal{X}\). Matematycznie należy więc znaleźć dobre rozszerzenie funkcji \(f\) z \(\mathcal{A}\) do całej przestrzeni \(\mathcal{X}\).
W praktyce dany mamy zbiór danych złożony z \(N\) próbek:
\[\begin{equation*}
\mathcal{D} = \left\{(x_i, y_i)\right\}_{i=1}^{N},
\end{equation*}\] przy czym \[\begin{equation*}
f(x_i)=y_i,
\end{equation*}\] dla \(i \leq N\).
Przestrzeń \(\mathcal{X}\) nazywana jest również przestrzenią cech, a jej elementy określa się mianem wektorów cech. Przestrzeń \(\mathcal{Y}\) nazywana jest również przestrzenią etykiet, a jej elementy określa się mianem etykiet. Okazuje się, że w kontekście nauczania maszynowego zamiast uczyć komputer zwracać konkretną wartość ze zbioru etykiet \(\mathcal{Y}\) wygodniej jest nauczyć go zwracać rozkład prawdopodobieństwa na \(\mathcal{Y}\). W ten sposób otrzymujemy więcej informacji, mamy kontrolę nad pewnością wyboru oraz możemy kontrolować przypadki brzegowe.
Przykład 2.3 Niech \(\mathcal{X}\) będzie przestrzenią wszystkich obrazów kotów i psów. Obraz możemy zapisać jako wektor: \[\begin{equation*}
\mathcal{X} = [0,1]^{3 \times H \times W},
\end{equation*}\] gdzie \(H\) to wysokość obrazu, \(W\) to szerokość, a \(3\) bierze się z trzech kanałów kolorów: RGB. Klasyfikator \(f\) ma przypisać obraz do jednej z dwóch klas: \[\begin{equation*}
\{\text{pies}, \text{kot}\}.
\end{equation*}\] Zamiast jednak zwracać od razu etykietę \(\text{pies}\) albo \(\text{kot}\), model często zwraca wektor prawdopodobieństw: \[\begin{equation*}
f(x) = (p_{\text{pies}}, p_{\text{kot}}).
\end{equation*}\] Na przykład \(f(x) = (0.87, 0.13)\) oznacza, że model ocenia obraz jako psa z prawdopodobieństwem \(0.87\), a jako kota z prawdopodobieństwem \(0.13\). Decyzję końcową otrzymujemy przez wybór największego prawdopodobieństwa: \[\begin{equation*}
y = \arg\max f(x).
\end{equation*}\] W naszym przykładzie \(y = \text{pies}\). Wektor prawdopodobieństw zawiera informację o pewności modelu. Przykładowo oba wyniki prowadzą do tej samej etykiety: \[\begin{equation*}
(0.51, 0.49) \mapsto \text{pies},
\end{equation*}\] oraz \[\begin{equation*}
(0.99, 0.01) \mapsto \text{pies}.
\end{equation*}\] Pierwszy przypadek oznacza, że model jest prawie niezdecydowany, a drugi, że jest bardzo pewny swojej decyzji.
Ta informacja jest przydatna, ponieważ można ustalić próg akceptacji decyzji. Na przykład jeżeli \[\begin{equation*}
\max \{ p_{\text{pies}}, p_{\text{kot}} \} < 0.8
\end{equation*}\] to model nie klasyfikuje automatycznie. Wtedy wynik \((0.51,0.49)\) można potraktować jako „nie wiem”, a wynik: \((0.99,0.01)\) jako pewną klasyfikację.
Ogólne podejście do rozwiązania tego problemu składa się z trzech głównych kroków.
Wybieramy model \[
F : \mathcal{X} \times \mathcal{W} \to \mathcal{Y}
\] parametryzowany przez parametr z przestrzeni \(\mathcal{W}\). Litera \(\mathcal{W}\) pochodzi od angielskiego słowa weights, ponieważ tak często określa się parametry w sieciach neuronowych.
Musimy określić ilościowo jakość wyjścia modelu, dlatego wybieramy funkcję straty\[
\ell : \mathcal{Y} \times \mathcal{Y} \to \mathbb{R},
\] gdzie \(\ell(y_1, y_2)\) określa, jak różne są \(y_1\) oraz \(y_2\).
Na podstawie zbioru danych \(\mathcal{D}\) oraz funkcji straty wybieramy \(w \in W\) tak, aby \[
F(\cdot, w)
\] było możliwie najlepszym przybliżeniem funkcji docelowej \(f\).
To wysokopoziomowe podejście pozostawia jednak kilka otwartych pytań.
Jak wybrać model?
Jak wybrać funkcję straty?
Jak przeprowadzić optymalizację?
Na żadne z tych pytań nie ma kanonicznych odpowiedzi. W dużej mierze rozwiązuje się je metodą prób i błędów oraz za pomocą heurystyk. Niezależnie od tego wybory te mają duży wpływ na końcowy wynik, mimo że nie są bezpośrednio uzasadnione przez dostępne dane ani przez jakieś podstawowe zasady. Zbiorczy zestaw założeń, które przyjmujemy, aby móc zająć się problemem, nazywa się w uczeniu maszynowym biasem indukcyjnym (inductive bias).
Na potrzeby tego kursu jako modele wybierzemy oczywiście sieci neuronowe; omówimy je dokładniej później. Drugą rzeczą, którą musimy zrobić, jest wybór funkcji straty. Funkcja straty działa podobnie do metryki, ale jest mniej restrykcyjna.
Zwykle (choć nie zawsze) mamy \(\ell(y)\geq 0\) dla każdego \(y \in \mathcal{Y}\).
Ponieważ chcemy minimalizować stratę, minimum powinno istnieć, tak aby wyrażenie \[
\min_{y \in Y} \ell(y_0, y)
\] było dobrze określone dla każdego \(y_0 \in \mathcal{Y}\).
Funkcja powinna być różniczkowalna, ponieważ chcemy stosować metody gradientowe.
Własności metryki, takie jak symetria czy nierówność trójkąta, nie muszą być spełnione.
Po wybraniu modelu i funkcji straty przechodzimy do optymalizacji, czyli pytania: jaki jest „najlepszy” wybór parametru \(w \in \mathcal{W}\)? Najprostsza, choć niekoniecznie preferowana, odpowiedź brzmi: należy zminimalizować stratę na zbiorze danych \(\mathcal{D} = \{(x_k,y_k) \}_{k \leq N}\), tzn. znaleźć \[\begin{equation*}
w^* = \arg\min_{w \in W}
\sum_{i=1}^{N} \ell(F(x_i; w), y_i).
\end{equation*}\]
Przykład 2.4 Niech \(w=(w_1, \ldots, w_n)\). Rozważmy model \[
F(x; w) = \sum_{j=1}^{n} w_j \varphi_j(x)
\] dla pewnych funkcji bazowych \(\{\varphi_j\}_{j\leq n}\). Przy funkcji straty \[
\ell(y_1, y_2) = |y_1 - y_2|^2
\] optymalizacja sprowadza się do metody najmniejszych kwadratów.
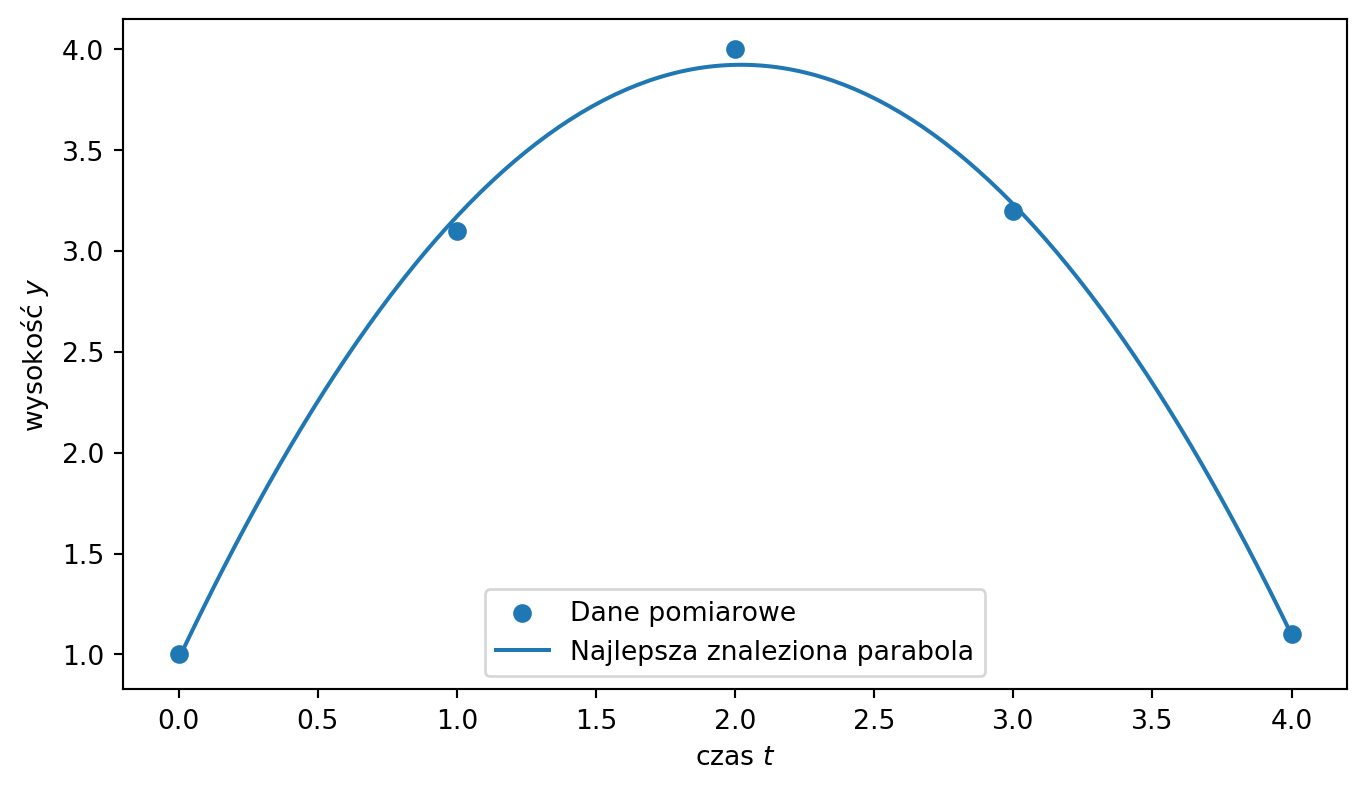
Przykład 2.5 Załóżmy, że mierzymy wysokość piłki w kolejnych chwilach czasu. Otrzymujemy dane pomiarowe: \[\begin{align*}
\mathcal{D} =& \{ (0,1.0), (1,3.1), (2,4.0), \\ & \: (3,3.2), (4,1.1) \}.
\end{align*}\] Pierwsza współrzędna oznacza czas \(t\), a druga wysokość piłki \(y\). Wiemy, że torem lotu piłki jest parabola (to jest nasz inductive bias!).
Jest to przykład polynomial fitting, czyli dopasowania wielomianu do danych. Możemy zapisać ten model w postaci: \[\begin{align*}
F(t;w)& =w_0+w_1t+w_2t^2 \\ &= \sum_{j=0}^{2} w_j \varphi_j(t),
\end{align*}\] gdzie funkcje bazowe to: \[\begin{align*}
& \varphi_0(t)=1, & \varphi_1(t)=t, \\ & \varphi_2(t)=t^2.
\end{align*}\] Parametry \(w_0,w_1,w_2\) nie są znane z góry. Model uczy się ich z danych, dobierając je tak, aby przewidywana wysokość \(F(t_i;w)\) była możliwie blisko zmierzonej wysokości \(y_i\).
W naszym przykładzie optymalizacja względem \(w = (w_1, w_2, w_3)\) sprowadza się do minimalizacji
Im mniejsza wartość \(L\), tym lepiej \(F( \cdot, w)\) opisuje tor lotu piłki. Zauważmy, że matematycznie \(L\) jest wielomianem kwadratowym trzech zmiennych. Dokładna optymalizacja sprowadza się do algebry liniowej.
Wektor \(y\) reprezentuje prawdziwe pomiary. Wektor \(\Phi w\) reprezentuje predykcje modelu. Wszystkie możliwe predykcje \(\Phi w\) tworzą pewną podprzestrzeń.
Szukamy punktu \(\Phi w\) w tej podprzestrzeni, który leży najbliżej \(y\). Jest to rzut prostopadły wektora \(y\) na przestrzeń generowaną przez kolumny macierzy \(\Phi\).
W tym podejściu nie używamy jeszcze gradientu. Minimalizacja polega po prostu na tym, że traktujemy \(w_0,w_1,w_2\) jak trzy pokrętła. Dla wielu ustawień tych pokręteł liczymy błąd \(L\), a potem wybieramy ustawienie z najmniejszym błędem.
Ten sposób nie jest wydajny dla dużych modeli, ale dobrze pokazuje podstawową ideę uczenia: szukamy takich parametrów \(w\), dla których model najlepiej pasuje do danych.
Po dopasowaniu otrzymujemy parabolę, która możliwie dobrze opisuje tor lotu piłki. Ważne jest to, że model nie musi przechodzić dokładnie przez każdy punkt pomiarowy, ponieważ dane mogą być zaszumione.
Ćwiczenie 2.1 Dla funkcji \(f(x) = \sin(x)\) na przedziale \([0,\pi]\) dobrać polynomial fitting stopnia co najwyżej trzy \[\begin{equation*}
p(x)= a_0+a_1x+a_2x^2+a_3x^3.
\end{equation*}\] Zaproponuj dane treningowe i zaimplementuj fitting. Porównaj wynik ze wzorem Taylora.
Najlepszy parametr dla modelu \(w \in \mathcal{W}\) niekoniecznie jest tym, który minimalizuje stratę na zbiorze danych treningowych. Zdarza się, że model uczy się zbyt dobrze konkretnych danych treningowych, ale przez to gorzej działa na nowych danych. Dzieje się tak zazwyczaj z kilku powodów:
Model ma zbyt wiele parametrów względem liczby danych treningowych
Dane zawierają błędy pomiarowe i przypadkowe fluktuacje
Dane treningowe nie są reprezentatywne
Przykład 2.6 Załóżmy, że nasze dane treningowe to \[\begin{equation*}
\mathcal{D} = \{ (0,0), (1,1), (2,2) \}.
\end{equation*}\] Dla takiego zbioru danych mamy całą rodzinę modeli \[\begin{equation*}
g_c(x) = x + cx(x-1)(x-2).
\end{equation*}\]
Przykład 2.7 Zdarza się, że nasze dane są lekko zaszumione w skutek błędów pomiarowych. Rozważmy \[\begin{equation*}
\mathcal{D} = \{ (0,0), (1,1), (2,2), (3,3.1) \}.
\end{equation*}\] Naturalny i najprostszy model to \(f(x)=x\). Wówczas jednak ostatni punkt z danych treningowych nie jest dopasowany idealnie. W klasie wielomianów trzeciego stopnia mamy \[\begin{equation*}
g(x) = x + \frac 1{60} x(x-1)(x-2).
\end{equation*}\] Dla którego \(g(x) =y\) dla wszystkich \((x,y) \in \mathcal{D}\). W tym momencie pytanie brzmi: czy poprawka \[\begin{equation*}
\frac 1{60} x(x-1)(x-2)
\end{equation*}\] odzwierciedla prawdziwą zależność, czy tylko dopasowuje się do małego odchylenia dla punktu \((3,3.1)\)? Wszystko zależy od tego skąd pochodzą dane. Jeżeli spodziewamy się zależności liniowej, to model \(g\) jest już przeuczony. Przykładowo \(f(4)=4\) ale \(g(4) = 4.4\). Jeżeli istotnie spodziewamy się zależności liniowej, to wartość \(g\) jest już zawyżona.
Sposobem na przeciwdziałanie przeuczeniu jest sekularyzacja.
Techniki regularyzacji dla sieci neuronowych omówimy szerzej później. Na razie wspomnimy tylko, że regularyzacja parametrów jest powszechną techniką znaną z regresji, często stosowaną również w sieciach neuronowych. Ten typ regularyzacji polega na dodaniu do straty na danych składnika karzącego, który zniechęca parametry do przyjmowania niepożądanych wartości, na przykład zbyt dużych. Zmodyfikowany problem optymalizacyjny ma postać
\[\begin{equation*}\min_{w \in \mathcal{W}}
\sum_{i=1}^{N} \ell(F(x_i; w), y_i) + \lambda C(w),
\end{equation*}\] gdzie \(\lambda > 0\) jest parametrem oraz \[\begin{equation*}
C : \mathcal{W} \to \mathbb{R}^{+}
\end{equation*}\] jest funkcją karzącą w pewien sposób złożoność modelu.
Przykład 2.8 Niech \(\mathcal{W} = \mathbb{R}^n\) oraz \[\begin{equation*}
C(w) = \|w\|^2.
\end{equation*}\] Dla \(n=1\) rozważmy dane z poprzedniego przykładu \[\begin{equation*}
\mathcal{D} = \{ (0,0), (1,1), (2,2), (3,3.1) \}
\end{equation*}\] oraz model \[\begin{equation*}
F(w,x) = x +wx(x-1)(x-2).
\end{equation*}\] Widzimy tu trend \(y=x\) w pierwszym składniku, który pozwalamy zaburzyć składnikiem wielomianowym widocznym po prawej stronie. Wiemy już, że bez regularyzacji najlepszy model otrzymujemy dla \(w=1/60\).
Sprawdźmy teraz jak wygląda optymalny punkt po zastosowaniu regularyzacji. Niech \[\begin{equation*}
L(w) = \sum_{(x,y) \in \mathcal{D}} (F(x,w) -y)^2 +\lambda w^2
\end{equation*}\] Ponieważ pierwsze trzy punkty są dopasowane idealnie dla każdego \(w\), to w \(L(w)\) zostaje tylko ostatni \[\begin{equation*}
L(w) = (3+6w-3.1)^2 +\lambda w^2.
\end{equation*}\] Dostajemy \[\begin{equation*}
w_\lambda = \frac{0.6}{36+\lambda}
\end{equation*}\] czyli \[\begin{equation*}
F(w_\lambda,x) = x +\frac{0.6}{36+\lambda} x(x-1)(x-2).
\end{equation*}\] Dla \(\lambda =0\) wracamy do modelu bez regularyzacji. Natomiast dla \(\lambda \to \infty\), \(F(w_\lambda,x) \to x\).
2.3 Statystyczna teoria uczenia
Rozważane przez nas do tej pory problemy leżą bardzo plisko teorii uczenia w statystyce. Zakłada się tam, że próbki danych \((x_i,y_i)\) są losowane niezależnie i z tego samego rozkładu prawdopodobieństwa \(\mu\) na \(\mathcal{X} \times \mathcal{Y}\). Jest to dość duże założenie (dlaczego?).
Interesuje nas wtedy minimalizacja ryzyka populacyjnego: \[\begin{align*}
R(w) & =
\mathbb{E}
\left[
\ell(F(X;w),Y)
\right]
\\ & =
\int_{\mathcal{X} \times \mathcal{Y}}
\ell(F(x;w),y)
\, \mu(\mathrm{d}x,\mathrm{d}y),
\end{align*}\] gdzie \((X,Y)\) jest wektorem o rozkładzie \(\mu\). Celem byłoby znalezienie zestawu parametrów, który minimalizuje to ryzyko populacyjne: \[
w^*
=
\arg\min_{w \in W} R(w).
\] W rzeczywistości jednak nie znamy rozkładu \(\mu\), więc nie możemy nawet obliczyć ryzyka populacyjnego dla zadanego parametru \(w\), nie mówiąc już o jego minimalizacji. Robimy zatem najlepszą dostępną rzecz: minimalizujemy ryzyko empiryczne: